ChatGPT in the Copyright Crossfire: Canadian News Giants Sue OpenAI Over AI Training Practices

Latestlaws



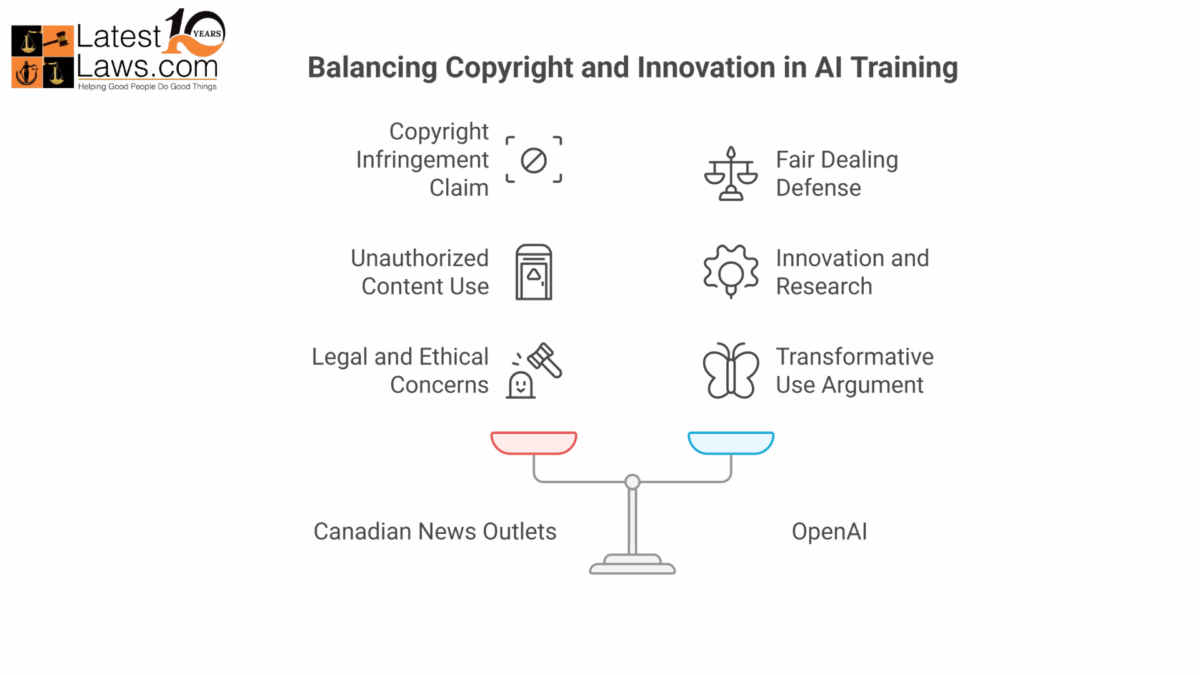
In a landmark legal move, five of Canada’s largest and most influential news organizations have filed a copyright infringement lawsuit against OpenAI—the creator of ChatGPT. The case, filed in late November 2024, accuses OpenAI of unauthorized use of protected content to train its AI models, with potential damages running into billions of dollars.
Read this: Audi’s “Q6” Trademark Battle
This lawsuit, brought forward by Torstar, Postmedia, The Globe and Mail Inc., The Canadian Press, and CBC/Radio-Canada, marks a pivotal moment in the evolving legal landscape surrounding AI and digital copyright. It follows similar high-profile legal actions, including one initiated earlier by The New York Times and other U.S. publishers, and may shape how future AI models are developed and regulated.
At the heart of the lawsuit is the accusation that OpenAI scraped large volumes of copyrighted material from media websites without obtaining permission or compensating content creators.
The news outlets claim:
By doing this, the plaintiffs argue, OpenAI has built and refined ChatGPT—a tool used by millions—at the expense of original journalism.
Web scraping refers to the use of automated bots or scripts that systematically collect information from web pages. For AI companies like OpenAI, scraping offers access to a vast dataset of human-written language—crucial for training large language models (LLMs) like ChatGPT.
However, Canadian news organizations assert that this goes beyond simple data collection. They argue that:
This raises a major legal and ethical question: Is using published journalism to train AI tools fair use, or a violation of copyright law?
The plaintiffs base their case on three primary legal arguments:
The news organizations argue that copying their work for commercial AI training constitutes unauthorized reproduction. Since OpenAI profits from ChatGPT subscriptions and enterprise partnerships, the media companies claim this use is commercial and exploitative.
Each website has clear terms of use. Most specify that content is for personal, non-commercial consumption only. By scraping and reusing this data, OpenAI is accused of breaching digital contracts that all users—including bots—are expected to follow.
Websites employ several anti-scraping tools, including the Robot Exclusion Protocol, paywalls, session tracking, and account-based access control. The lawsuit claims OpenAI intentionally circumvented these barriers, which could also invoke anti-circumvention laws under the Canadian Copyright Act.
OpenAI, although not yet responding formally to this specific lawsuit, has addressed similar accusations elsewhere—especially in the U.S. lawsuits filed by major publishers. Its main argument is that the use of online content for AI training falls under “fair use” (U.S.) or “fair dealing” (Canada).
Here’s their reasoning:
However, Canadian courts evaluate fair dealing under a six-factor test:
In this case, the commercial nature, volume of data scraped, and economic harm to publishers may work against OpenAI.
This case has the potential to set global legal precedents. It pits two powerful forces against each other:
The core issue is this: Can generative AI be trained on copyrighted content without permission or payment?
If courts decide against OpenAI:
If OpenAI prevails:
This case highlights a growing concern among digital creators—how AI tools use their work without acknowledgment or reward. It also raises questions for SEO experts, webmasters, and marketers:
As AI becomes more integrated into content generation, search engine algorithms, and online engagement, original publishers must rethink their digital rights frameworks.
The lawsuit filed by Canada’s top media outlets against OpenAI is not just a local news story—it’s a global copyright showdown with far-reaching consequences. It will test the boundaries between innovation and exploitation, fair dealing and infringement, and public access and proprietary rights.
As courts begin to assess the legal and ethical dimensions of this case, the decision could reshape how AI companies source data, how media companies protect content, and how laws evolve to balance both innovation and authorship.
For now, both the tech and media industries await what may become a landmark ruling in the age of artificial intelligence.





